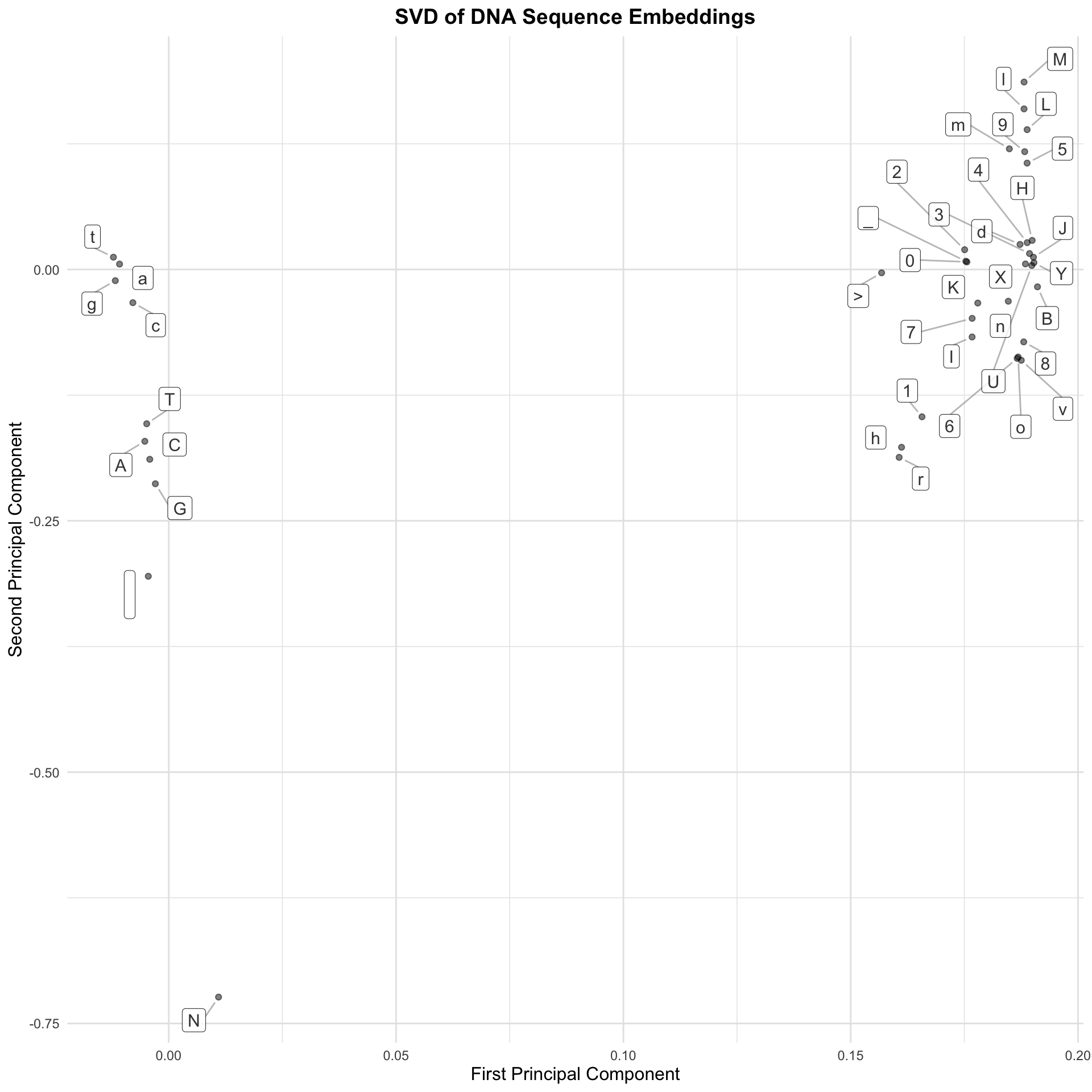
** embeddings provided by Henry from his DNA GPT model**
suppressMessages(library(tidyverse))
Warning: package 'purrr' was built under R version 4.3.3
Warning: package 'lubridate' was built under R version 4.3.3
suppressMessages(library(glue))
Warning: package 'glue' was built under R version 4.3.3
suppressMessages(library(ggrepel))
Warning: package 'ggrepel' was built under R version 4.3.3
# suppressMessages(library(qvalue))# suppressMessages(library(devtools))# suppressMessages(source_gist("38431b74c6c0bf90c12f")) ## get qqunif# suppressMessages(library(googlesheets4))WEBDATA ="/Users/haekyungim/Library/CloudStorage/Box-Box/LargeFiles/imlab-data/data-Github/web-data"DATA =glue("{WEBDATA}/web-GENE-46100")if(!file.exists(DATA)) system(glue::glue("mkdir {DATA}"))##system(glue("open {DATA}")) ## this will open the folder