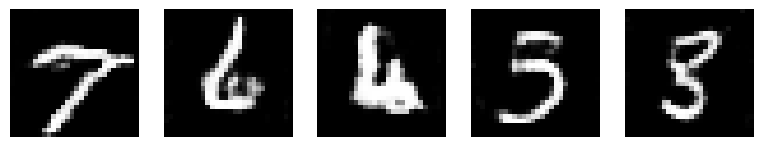import torch
from torch import nn, optim
import torchvision.transforms as transforms
import torchvision
import matplotlib.pyplot as pltgan example mnist
notebook
# Custom Reshape layer
class Reshape(nn.Module):
def __init__(self, *args):
super(Reshape, self).__init__()
self.shape = args
def forward(self, x):
return x.view(x.shape[0], *self.shape)
# Define Generator network with convolutional layers
class Generator(nn.Module):
def __init__(self, z_dim=100):
super(Generator, self).__init__()
self.gen = nn.Sequential(
# First layer
nn.Linear(z_dim, 7*7*256),
nn.BatchNorm1d(7*7*256),
nn.ReLU(True),
# Reshape to start convolutions
Reshape(256, 7, 7),
# Convolution layers
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 1, kernel_size=3, stride=1, padding=1),
nn.Tanh()
)
def forward(self, x):
return self.gen(x)
# Define Discriminator network with convolutional layers
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.disc = nn.Sequential(
# First conv layer
nn.Conv2d(1, 64, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.3),
# Second conv layer
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.3),
# Flatten and dense layers
nn.Flatten(),
nn.Linear(128 * 7 * 7, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(1024, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.disc(x)
# Hyperparameters
z_dim = 100
lr = 2e-4 # Slightly adjusted learning rate
beta1 = 0.5 # Beta1 for Adam optimizer
batch_size = 128 # Increased batch size
epochs = 20 # Increased epochs
# Set up device
device = torch.device("mps")
# Data loading with normalization [-1, 1]
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
dataset = torchvision.datasets.MNIST(root='data/', train=True, transform=transform, download=True)
loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
# Initialize models and move to MPS
generator = Generator(z_dim).to(device)
discriminator = Discriminator().to(device)
# Optimizers with beta1
optimG = optim.Adam(generator.parameters(), lr=lr, betas=(beta1, 0.999))
optimD = optim.Adam(discriminator.parameters(), lr=lr, betas=(beta1, 0.999))
# Loss function
criterion = nn.BCELoss()
# Training loop with improved stability
for epoch in range(epochs):
for batch_idx, (real_images, _) in enumerate(loader):
batch_size_current = real_images.shape[0]
# Move data to MPS
real_images = real_images.to(device)
# Train Discriminator
discriminator.zero_grad()
label_real = torch.ones(batch_size_current, 1).to(device)
label_fake = torch.zeros(batch_size_current, 1).to(device)
output_real = discriminator(real_images)
d_loss_real = criterion(output_real, label_real)
noise = torch.randn(batch_size_current, z_dim).to(device)
fake_images = generator(noise)
output_fake = discriminator(fake_images.detach())
d_loss_fake = criterion(output_fake, label_fake)
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
optimD.step()
# Train Generator
generator.zero_grad()
output_fake = discriminator(fake_images)
g_loss = criterion(output_fake, label_real)
g_loss.backward()
optimG.step()
if batch_idx % 100 == 0:
print(f'Epoch [{epoch}/{epochs}] Batch [{batch_idx}/{len(loader)}] '
f'd_loss: {d_loss.item():.4f} g_loss: {g_loss.item():.4f}')
# Generate and save sample images after each epoch
if (epoch + 1) % 5 == 0:
with torch.no_grad():
test_noise = torch.randn(5, z_dim).to(device)
generated_images = generator(test_noise)
plt.figure(figsize=(10, 2))
for i in range(5):
plt.subplot(1, 5, i + 1)
# Move tensor back to CPU for plotting
plt.imshow(generated_images[i].cpu().squeeze().numpy(), cmap='gray')
plt.axis('off')
plt.show()Epoch [0/20] Batch [0/469] d_loss: 1.4587 g_loss: 0.7364
Epoch [0/20] Batch [100/469] d_loss: 1.3710 g_loss: 0.7146
Epoch [0/20] Batch [200/469] d_loss: 1.1290 g_loss: 0.8700
Epoch [0/20] Batch [300/469] d_loss: 0.9860 g_loss: 1.1322
Epoch [0/20] Batch [400/469] d_loss: 0.4725 g_loss: 1.9018
Epoch [1/20] Batch [0/469] d_loss: 0.5324 g_loss: 1.8864
Epoch [1/20] Batch [100/469] d_loss: 0.3427 g_loss: 2.4291
Epoch [1/20] Batch [200/469] d_loss: 0.2379 g_loss: 2.6575
Epoch [1/20] Batch [300/469] d_loss: 0.2059 g_loss: 3.3945
Epoch [1/20] Batch [400/469] d_loss: 0.1537 g_loss: 3.2048
Epoch [2/20] Batch [0/469] d_loss: 0.3866 g_loss: 2.3630
Epoch [2/20] Batch [100/469] d_loss: 0.2228 g_loss: 2.8267
Epoch [2/20] Batch [200/469] d_loss: 0.1287 g_loss: 3.4258
Epoch [2/20] Batch [300/469] d_loss: 0.1049 g_loss: 3.9926
Epoch [2/20] Batch [400/469] d_loss: 0.2627 g_loss: 3.3500
Epoch [3/20] Batch [0/469] d_loss: 0.1071 g_loss: 3.8937
Epoch [3/20] Batch [100/469] d_loss: 0.1239 g_loss: 3.4904
Epoch [3/20] Batch [200/469] d_loss: 0.0526 g_loss: 4.2760
Epoch [3/20] Batch [300/469] d_loss: 0.1703 g_loss: 3.7801
Epoch [3/20] Batch [400/469] d_loss: 1.5493 g_loss: 0.7978
Epoch [4/20] Batch [0/469] d_loss: 1.4743 g_loss: 0.8553
Epoch [4/20] Batch [100/469] d_loss: 1.5439 g_loss: 0.8430
Epoch [4/20] Batch [200/469] d_loss: 1.5271 g_loss: 0.8607
Epoch [4/20] Batch [300/469] d_loss: 1.3586 g_loss: 0.7892
Epoch [4/20] Batch [400/469] d_loss: 1.3883 g_loss: 0.8830
Epoch [5/20] Batch [0/469] d_loss: 1.5093 g_loss: 0.9424
Epoch [5/20] Batch [100/469] d_loss: 1.4322 g_loss: 1.0056
Epoch [5/20] Batch [200/469] d_loss: 1.3403 g_loss: 0.9821
Epoch [5/20] Batch [300/469] d_loss: 1.3601 g_loss: 0.8536
Epoch [5/20] Batch [400/469] d_loss: 1.3104 g_loss: 0.7968
Epoch [6/20] Batch [0/469] d_loss: 1.1751 g_loss: 0.9554
Epoch [6/20] Batch [100/469] d_loss: 1.3790 g_loss: 0.9607
Epoch [6/20] Batch [200/469] d_loss: 1.2350 g_loss: 0.7746
Epoch [6/20] Batch [300/469] d_loss: 1.2191 g_loss: 0.8583
Epoch [6/20] Batch [400/469] d_loss: 1.2714 g_loss: 0.9669
Epoch [7/20] Batch [0/469] d_loss: 1.3526 g_loss: 0.8643
Epoch [7/20] Batch [100/469] d_loss: 1.3798 g_loss: 0.9228
Epoch [7/20] Batch [200/469] d_loss: 1.3123 g_loss: 0.8387
Epoch [7/20] Batch [300/469] d_loss: 1.2502 g_loss: 0.9403
Epoch [7/20] Batch [400/469] d_loss: 1.3042 g_loss: 0.9029
Epoch [8/20] Batch [0/469] d_loss: 1.2249 g_loss: 0.8839
Epoch [8/20] Batch [100/469] d_loss: 1.2266 g_loss: 0.8993
Epoch [8/20] Batch [200/469] d_loss: 1.2863 g_loss: 0.8482
Epoch [8/20] Batch [300/469] d_loss: 1.2024 g_loss: 0.9778
Epoch [8/20] Batch [400/469] d_loss: 1.1278 g_loss: 0.8528
Epoch [9/20] Batch [0/469] d_loss: 1.1930 g_loss: 0.9338
Epoch [9/20] Batch [100/469] d_loss: 1.3779 g_loss: 0.8452
Epoch [9/20] Batch [200/469] d_loss: 1.2220 g_loss: 1.0130
Epoch [9/20] Batch [300/469] d_loss: 1.2013 g_loss: 0.9121
Epoch [9/20] Batch [400/469] d_loss: 1.2612 g_loss: 1.0147
Epoch [10/20] Batch [0/469] d_loss: 1.1912 g_loss: 0.9411
Epoch [10/20] Batch [100/469] d_loss: 1.1474 g_loss: 0.9353
Epoch [10/20] Batch [200/469] d_loss: 1.2389 g_loss: 0.8523
Epoch [10/20] Batch [300/469] d_loss: 1.1961 g_loss: 0.7835
Epoch [10/20] Batch [400/469] d_loss: 1.1892 g_loss: 0.9633
Epoch [11/20] Batch [0/469] d_loss: 1.1884 g_loss: 0.8253
Epoch [11/20] Batch [100/469] d_loss: 1.2928 g_loss: 0.9628
Epoch [11/20] Batch [200/469] d_loss: 1.1756 g_loss: 0.9246
Epoch [11/20] Batch [300/469] d_loss: 1.2237 g_loss: 0.9206
Epoch [11/20] Batch [400/469] d_loss: 1.1077 g_loss: 0.9726
Epoch [12/20] Batch [0/469] d_loss: 1.2371 g_loss: 1.0076
Epoch [12/20] Batch [100/469] d_loss: 1.2275 g_loss: 0.9172
Epoch [12/20] Batch [200/469] d_loss: 1.2303 g_loss: 0.9334
Epoch [12/20] Batch [300/469] d_loss: 1.1339 g_loss: 0.9581
Epoch [12/20] Batch [400/469] d_loss: 1.2166 g_loss: 1.0264
Epoch [13/20] Batch [0/469] d_loss: 1.2645 g_loss: 0.8292
Epoch [13/20] Batch [100/469] d_loss: 1.2263 g_loss: 0.9388
Epoch [13/20] Batch [200/469] d_loss: 1.2474 g_loss: 0.9823
Epoch [13/20] Batch [300/469] d_loss: 1.2536 g_loss: 0.9741
Epoch [13/20] Batch [400/469] d_loss: 1.2097 g_loss: 0.9343
Epoch [14/20] Batch [0/469] d_loss: 1.2619 g_loss: 0.9633
Epoch [14/20] Batch [100/469] d_loss: 1.3268 g_loss: 0.9094
Epoch [14/20] Batch [200/469] d_loss: 1.2769 g_loss: 0.9404
Epoch [14/20] Batch [300/469] d_loss: 1.1858 g_loss: 0.9609
Epoch [14/20] Batch [400/469] d_loss: 1.2346 g_loss: 1.0119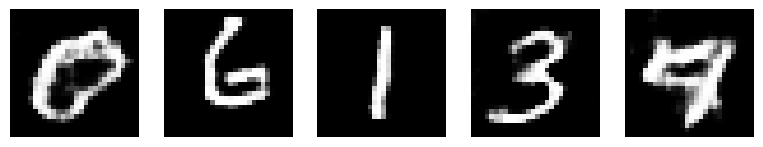
Epoch [15/20] Batch [0/469] d_loss: 1.1835 g_loss: 0.9720
Epoch [15/20] Batch [100/469] d_loss: 1.2663 g_loss: 0.9126
Epoch [15/20] Batch [200/469] d_loss: 1.2762 g_loss: 0.8213
Epoch [15/20] Batch [300/469] d_loss: 1.1572 g_loss: 0.8374
Epoch [15/20] Batch [400/469] d_loss: 1.0717 g_loss: 0.9020
Epoch [16/20] Batch [0/469] d_loss: 1.2640 g_loss: 0.9940
Epoch [16/20] Batch [100/469] d_loss: 1.2792 g_loss: 1.0197
Epoch [16/20] Batch [200/469] d_loss: 1.3113 g_loss: 0.9563
Epoch [16/20] Batch [300/469] d_loss: 1.2178 g_loss: 0.9577
Epoch [16/20] Batch [400/469] d_loss: 1.2632 g_loss: 0.9852
Epoch [17/20] Batch [0/469] d_loss: 1.2279 g_loss: 0.9235
Epoch [17/20] Batch [100/469] d_loss: 1.3499 g_loss: 0.9113
Epoch [17/20] Batch [200/469] d_loss: 1.1605 g_loss: 0.9119
Epoch [17/20] Batch [300/469] d_loss: 1.2327 g_loss: 0.8470
Epoch [17/20] Batch [400/469] d_loss: 1.1778 g_loss: 0.9232
Epoch [18/20] Batch [0/469] d_loss: 1.4804 g_loss: 0.8219
Epoch [18/20] Batch [100/469] d_loss: 1.3487 g_loss: 0.8752
Epoch [18/20] Batch [200/469] d_loss: 1.2347 g_loss: 0.8730
Epoch [18/20] Batch [300/469] d_loss: 1.2076 g_loss: 0.9315
Epoch [18/20] Batch [400/469] d_loss: 1.2874 g_loss: 0.8813
Epoch [19/20] Batch [0/469] d_loss: 1.2302 g_loss: 1.0094
Epoch [19/20] Batch [100/469] d_loss: 1.2215 g_loss: 0.8352
Epoch [19/20] Batch [200/469] d_loss: 1.2204 g_loss: 0.9764
Epoch [19/20] Batch [300/469] d_loss: 1.3497 g_loss: 0.8585
Epoch [19/20] Batch [400/469] d_loss: 1.2276 g_loss: 0.9919